Remplacement LAN + Firewall Paris et Nantes


Des équipements en fin de vie
Dans le cadre d’un plan global de modernisation des réseaux locaux de l’entreprise (LAN) des différents sites, j’ai procédé au remplacement des switchs du LAN encore sous le système d’exploitation (OS) Comware 5 lors de mon alternance.
Il a donc été décidé de les remplacer pour passer à une version plus récente de Comware (v5 à v7) qui est plus ergonomique, mieux maintenue et plus évolutive (compatible avec l’automatisation via Netconf, une solution d’automatisation universelle).
Ce remplacement a porté sur l’intégralité du parc du site de Nantes ainsi que quelques switchs sur Paris et Saint-Denis.
Peu de temps après cette décision, notre fournisseur de firewall bureautique, PaloAlto, a décidé de rendre obsolètes lors la prochaine version majeure nos firewall actuellement en production.
Nos firewall actuels posaient souvent des problèmes de saturations de leurs interfaces. En effet, nous utilisons nos firewall comme routeurs et donc le routage inter VLAN est assuré par eux même.
La décision a donc été de passer sur un modèle disposant de ports 10 Gb/s à mettre dans un agrégat, (un ensemble de ports physique permettant de faire un port virtuel unifié) afin de prévenir notamment de tous risques de saturation lors des mises à jour du parc Windows.
Les modèles de switchs cœurs retenus, des HPE 5510 disposant de peu d’interfaces 10Gb/s (4 par défaut) et devant notre volonté de passer les switchs d’accès également sur des uplink 10Gb/s, (liens entre la couche accès et les cœurs) nous avons fait le choix de passer par des interfaces 40Gb/s, que l’on peut rajouter sous forme de cartes à insérer à l’arrière du switch, que nous avons ensuite découper en 4x10Gb/s sur chaque interface.
Le découpage est réalisé via un séparateur dont le but est de séparer les 4 signaux 10Gb/s présent en sortie de l’interface de l’optique « SR4 » (lumière courte distance x4) en 4 connecteurs ‘LC’ classique contenant chacun une lumière « SR » classique.
Le grand remplacement
Le remplacement a porté sur 33 switchs, dont 2 switchs coeurs, et 2 firewalls en cluster (mode haute disponibilité avec un membre de secours) à remplacer sur des temps limités (pause du midi). Nous avons procédé local technique par local technique, avec des techniciens présents sur place pour le site de Nantes et un remplacement par moi-même pour les sites de Paris et Saint-Denis.
Il faut donc leur donner la marche à suivre pour le remplacement, avec mon accompagnement par téléphone avec un contrôle au fur et à mesure du remplacement pour vérifier que tout ce passe bien.
J’ai procédé à la réception du matériel sur Paris, puis à leurs configurations suivant l’utilisation actuelle des ports sur les switchs existant, ainsi que leur mise à jour vers la dernière version publiée par HP.
Même procédure pour les Firewall, mais cette fois-ci avec une légère adaptation de la configuration pour adapter l’ancienne configuration avec le nouveau modèle de firewall.
La procédure est assez simple, il suffit d’extraire le fichier XML de configuration, et de reprendre les éléments que l’on veut réinjecter dans le matériel neuf, en modifiant les interfaces pour notre cas.
Le rackage des nouveaux switchs coeurs est réalisé en amont afin de pouvoir tester le splitter (permet de convertir les ports d’un type à un autre) avant le début de l’intervention.
Il est en effet très simple de savoir si tout fonctionne correctement, la lumière émise par une optique SR est visible à travers un simple appareil photo de téléphone portable.
Pour la couche accès (l’ensemble de switch sur lequel les utilisateurs sont connectés), on procède de manière différente, comme nous disposons de beaucoup de place dans la baie, nous commençons par racker le dernier switch contenant les ports spécifiques juste en dessous du dernier switch existant.
Ensuite nous branchons le switch sur ceux existants, on déplace les ports spécifiques sur le nouveau switch (imprimantes, bornes wifi, salle de conférence …).
Une fois réalisé, il ne reste plus que des prises utilisateurs standard, que l’on peut brancher n’importe où, sans se soucier de leur emplacement.
Une fois l’ancien switch vide, nous l’éteignons, nous le dérackons, on rack un switch neuf à sa place, et on répète la manœuvre.
La partie du remplacement la plus compliqué à été celle du cœur de réseau de Nantes, avec le minimum de coupures possibles (obligatoire car tout ce qui est branché dessus n’est pas forcément redondé) et avec un technicien qui n’avait pas beaucoup d’expérience en réseau.
Pour la partie Firewall, il a été nécessaire d’attendre le remplacement des anciens cœurs, qui ne disposaient pas de ports 10 Gb/s.
L’intervention de remplacement des Firewall a consisté à débrancher les interfaces sur les anciens Firewall puis de les rebrancher dans la foulée sur le Firewall neuf.
Un réseau neuf, fait pour durer
Le réseau tel qu’il a été réalisé est paré pour l’avenir, toutes les prises utilisateurs sont maintenant en Gigabit Ethernet et les uplinks (liaisons entre les switchs coeurs et les switchs d’accès) sont tous en 10 Gb/s.
Idem pour le Firewall, qui possède maintenant un agrégat 20Gb/s (2x10Gb/s) pour ses interfaces d’entrées/sorties avec une puissance de calcul suffisante pour pouvoir digérer ce trafic.
Mon tuteur m’a laissé carte blanche sur ce projet et m’a donc fait totalement confiance pour toute sa gestion.
Compétences : Autonomie, Planification, Force de proposition, Sécurité – pare-feux PaloAlto, Réseau – HP Comware
Remplacement du parc de Bornes Wi-Fi et du HiveManager

Un parc vieillissant et peu uniforme
Dans le but de pouvoir profiter de la dernière technologie Wi-Fi de l’époque, le Wi-Fi AC, on m’a demandé de procéder au remplacement de l’intégralité du parc de bornes Wi-Fi suite à une demande de la Direction Technique.
Un plan d’installation des bornes nous a donc été fourni pour indiquer où les placer sur nos plafonds.
Le parc était composé de 150 bornes Wi-Fi étalées sur 4 sites et de générations diverses et variées, suivant le moment où elles ont été acheté les bornes au fur et à mesure des agrandissements.
Une prestation de câblage a également été commandé auprès d’un électricien afin de fixer les bornes au plafond. En effet, avant ce remplacement, les bornes étaient posées sur des bureaux ou dans des faux plafonds, ce qui rendaient les diffusions des signaux wifi parfois compliqués.
La marque des bornes a été conservée, AeroHive afin de pouvoir réutiliser notre logiciel de gestion HiveManager On Premise.
Activité industrielle
Lors de la livraison des bornes, il a fallu les paramétrer et les étiqueter suivant leur lieu d’installation.
J’ai industrialisé cette procédure en installant un switch PoE (délivrant de l’électricité via ses ports réseaux) 24 ports et les branchant à la chaîne.
Les bornes une fois connectées au réseau sans configuration, cherchent d’elles-mêmes à se connecter au serveur « hivemanager.monreseau.local », où elles apparaissent automatiquement sur l’interface de gestion.
Coté HiveManager, il ne reste plus qu’à renommer les bornes et leur envoyer la configuration générique commune à toutes les bornes ainsi que la configuration spécifique de chaque site. Cela m’a permis de configurer toutes les bornes en environ 14h.
Quelques temps plus tard, j’ai entrepris de remplacer notre HiveManager « Classic » par la version « NG » afin de pouvoir profiter d’une gestion complète de nos bornes Wi-Fi.
En effet, celles-ci n’étaient pas pleinement exploitées par cette ancienne version que ne permettait pas de disposer de la dernière version du système d’exploitation des bornes, ce qui causait des plantages répétés de celles-ci.
Nous sommes partis de nouveau sur une version On Premise (« Cloud Privé ») installée sur nos hyperviseurs ESXi (logiciel de virtualisation).
Une démonstration de faisabilité a été réalisé sur une borne de test, puis sur un étage désaffecté, afin de vérifier le comportement des bornes lors du changement du contrôleur mais aussi de vérifier la procédure fournie par AeroHive.
Cette nouvelle version nous a également permis de mieux gérer nos SSID (noms de réseaux Wi-Fi) via une gestion en mode « objet ». En effet, l’ancienne interface refusait que l’on ait plusieurs fois le même SSID avec différentes configurations. Cette conception du logiciel était problématique car cela forçait à ce que le serveur d’authentification RADIUS soit le même sur tous les sites.
Avec cette avancée, nous avons pu unifier nos identités réseaux et ainsi permettre une gestion spécifique des serveurs d’authentification sur chaque site afin de garder un haut niveau de disponibilité en cas de perte de connectivité avec notre réseau MPLS national (méthode d’envoi des paquets Ethernet sous forme de messages sur un réseau privé).
Cette migration a été faite zone par zone et site par site sur le temps du midi sans réel soucis, hormis des faux contacts de câbles Ethernet empêchant le redémarrage des bornes, ce qui oblige à intervenir physiquement pour la remettre en marche.
Un gain en qualité de service non négligeable
Ce remplacement a permis un gain en terme de qualité de service grâce à un parc de bornes neuves, uniformes, bien placées et à jour. Cela nous a permis également d’uniformiser l’identité des réseaux suivant les sites et d’augmenter la résilience en cas de panne d’un serveur RADIUS ou d’une perte de liaison MPLS.
Compétences : Autonomie, Planification, Réseau – Wifi AeroHive
Remplacement de la supervision Cacti par LibreNMS

Cacti, un logiciel instable et en perte de vitesse
L’équipe Réseau a souhaité remplacer la solution de supervision Cacti actuellement en place par une autre plus récente, et surtout maintenue et en évolution.
Cacti posait de nombreux problèmes de stabilité avec des pertes de graphiques aléatoires et une compatibilité imparfaite avec les équipements récents du nouveau datacenter en cours d’aménagement.
De plus, l’objectif était aussi d’envoyer à l’équipe d’astreinte 24/7 des alertes en cas de problèmes sur l’infrastructure réseau de production, ce qui n’était pas possible avec Cacti en raison de ses problèmes de stabilité.
L’équipe système souhaitait également voir disparaître les serveurs basés sur CentOS 5, ce qui était le cas de la machine qui hébergeait Cacti.
Un avantage non négligeable de LibreNMS est sa grande compatibilité avec la plupart des constructeurs du marché. Dans le cas où un équipement n’est pas pris en charge, le logiciel étant libre, il est possible de coder soi-même l’élément puis de le proposer sur le GitHub du projet.
Les administrateurs du projet sont réactifs et acceptent sans soucis que l’on modifie l’existant ou que l’on ajoute des fonctionnalités.
Un projet destiné à un échec certain
Lors de mon arrivée dans l’entreprise, une démonstration de faisabilité avait déjà été effectué par un membre de l’équipe, mais celui-ci présentait de gros problèmes de stabilité et de montée en charge.
Cette architecture était basée sur des machines virtuelles en mode « distribué » avec des spécialités par poller (serveur procédant à la vérification), la production, la hors production et la bureautique.
En effet, nous avons régulièrement des plantages complets des machines virtuelles souvent causés par une seule machine, qui faisait alors planter le reste de l’infrastructure par impossibilité de reprendre la charge (malgré le fait que la capacité soit quand même largement suffisante).
Nous étions également limités par des spécificités de l’architecture VMWare de l’équipe Système, à savoir une limite de 4 cœurs et 8Go de mémoire vive par machine virtuelle.
LibreNMS est un logiciel fortement multitheardé (est capable d’utiliser plus d’un seul cœur processeur à la fois). Il est donc fortement conseillé de posséder un grand nombre de cœurs pour faire fonctionner efficacement le logiciel.
Dans le but d’avoir le même niveau de supervision de Cacti, l’équipe a également demandé un polling (action de vérification sur l’équipement) avec un intervalle de 1 minute, ce qui pour le cas de LibreNMS nécessite une optimisation parfaite de l’infrastructure de supervision.
Dans le cas où une machine met plus d’une minute à être vérifiée, alors du retard est donc pris sur la supervision, qui sera quasiment impossible à rattraper. LibreNMS ne cherche pas à savoir si la vérification précédente est terminée pour en lancer une autre, les processus de vérifications s’accumulent en mémoire vive et finissent par faire planter la machine.
Une tentative de mise en production a même été réalisée, mais elle a laissé des souvenirs douloureux à l’équipe, avec des gros problèmes de faux positifs, ce qui a entaché grandement l’image du logiciel dans l’équipe avec des réveils intempestifs en pleine nuit par l’astreinte 24/7.
La personne en charge de ce projet étant sur le départ, l’équipe a choisi de redonner le projet à un autre collègue et à moi.
La reprise en main du projet
Après de multiples tentatives de stabilisation, nous en sommes venus à la conclusion que l’architecture retenue n’était pas stabilisable et qu’il fallait repartir de zéro.
De plus, la qualité de la documentation de ce qui avait été fait, variait de très imprécis/pas à jour à inexistante. Cette documentation a rendu très compliqué l’exploitation de cette architecture et son débug.
Notre franc-parler a permis de vite repartir sur des bases saines et de faire avancer le projet plus rapidement. Nous savions pertinemment que cela ne pourrait pas fonctionner correctement mais l’équipe n’était pas prête à entendre que ce qui avait été fait n’était pas viable.
Nous avons choisi dans un premier temps de repasser sur une architecture physique centralisée et de séparer les environnements de production/hors production et de bureautique avec une configuration synchronisée entre les deux instances de chaque environnement.
Diverses actions ont été automatisées pour aider à la gestion au quotidien comme les synchronisations des instances, les mises à jour ou même le déploiement complet du logiciel sous CentOS 7.
LibreNMS servira aussi, de manière provisoire de serveur de Syslog (messages émis par les équipements pour informer de leur état) le temps qu’une vraie infrastructure de Syslog dédiée soit mise en place.
La documentation a été en conséquence totalement refaite avec la création d’un guide utilisateur pour les utilisateurs du service.
Mon collègue et moi avons également ajouté des fonctionnalités ou corrigé des bugs afin de pouvoir le faire mieux coller à nos besoins.
De la stabilité mais une confiance entachée
A la suite de ces grands changements d’infrastructure, nous avons enfin eu une solution stable et performante de supervision.
Malgré cela, l’équipe a eu beaucoup de mal à faire confiance à ce logiciel à cause de la première expérience ratée et des astreintes déclenchée pour rien.
Il aura fallu attendre un turnover important et un renouvellement de l’équipe pour que LibreNMS soit pris au sérieux.
Aujourd’hui les alertes fonctionnent, elles sont maintenant prises au sérieux et les serveurs sont stables.
Compétences : Esprit d’analyse, Franchise, Force de proposition, Linux – CentOS, Supervision – LibreNMS
Remplacement des solutions MPLS Orange par des pFON

Un réseau WAN qui ne correspond plus aux besoins
L’équipe réseau, par soucis d’économie et de gain en qualité de service, a souhaité remplacer ses accès MPLS (méthode d’envoi des paquets Ethernet sous forme de messages sur un réseau privé) Orange Business Service (OBS) « Business VPN » par des pFON (paires de fibres optiques noires).
En effet, OBS proposait ce service à un prix très élevé et avec un débit trop faible (160 Mb/s sur les gros sites, 20Mb/s sur les petits) par rapport à notre besoin en bande passante, en constante augmentation avec l’explosion des besoins en services numériques.
Nos sites parisiens avaient l’avantage d’être tous à moins de 50km de notre datacenter télécom situé à Courbevoie ce qui rend assez simple l’éclairage de la fibre optique par nous-même, car les équipements optique (SFP) sont trouvables facilement et pour un coût très raisonnable.
La pFON permet également à celui qui la loue de pouvoir éclairer sa fibre comme il le souhaite, avec la technologie de son choix (1Gb/s, 10Gb/s, 100Gb/s …)
Un plan de remplacement des accès par de la fibre optique noire a donc été lancé avec un démarchage des différents acteurs du marché, c’est finalement Sipartech qui a été retenu.
Le cas de Saint-Denis
J’ai eu l’occasion pendant mon alternance de pouvoir procéder au remplacement du lien MPLS pour le site de Saint-Denis situé à proximité du siège du Groupe SNCF.
Afin d’économiser sur les le nombre de pFON, nous avons fait le choix de passer par la technologie WDM (multiplexage par longueur d’onde) qui permet de mutualiser une paire de fibre pour faire passer plusieurs « couleurs » à la fois et donc plusieurs fois 1G ou 10G.
Une visite de chantier a eu lieu avant de tirer le lien pour pouvoir effectuer une étude technique et savoir comment le bâtiment est connecté au réseau de génie civil d’Orange, pour pouvoir prévoir d’avance le chemin optique et pour obtenir les autorisations nécessaires (administratives et celle de SNCF pour le bâtiment).
Le tirage de Sipartech a été réalisé entre un datacenter proche (la zone de Saint-Denis/Aubervilliers est très peuplée en datacenter) et notre bâtiment, le reste du trajet est réalisé grâce au réseau de fibre inter datacenter de Sipartech.
Une mise en service … compliquée
Cette mise en service a été longue et compliquée, Sipartech a pris beaucoup de retard sur le tirage, en raison de nombreux dépôts sauvages d’ordures sur le chemin de la fibre. La gestion de projet du coté de Sipartech a aussi été catastrophique, avec deux rendez-vous manqués devant les bureaux de la SNCF. Le tirage a finalement été réalisé par un prestataire qui ne communiquait pas avec le chef de projet de Sipartech.
Une fois tirée, Sipartech nous a recontacté pour nous dire qu’ils ne pouvaient pas livrer le lien, les soudures réalisées dans le bâtiment étaient mauvaises, il a fallu y retourner et refaire les 144 soudures, ce qui nous à fait perdre une demi journée de travail.
Est venu ensuite la livraison du lien fibre, en tout cas en théorie, car dans les faits, impossible de le faire monter, la lumière semblait passer dans un sens mais pas dans l’autre.
Le lien était maintenant sous GTR (Garantie du Temps de Rétablissement) vu qu’ officiellement livré et facturé, nous leur avons demandé de le (re)mettre en fonction.
Ils ont d’abord demandé de lancer une demande de vérification du CrossConnect (lien inter baie en datacenter) auprès de Equinix (l’entreprise propriétaire du datacenter).
Equinix a procédé aux vérifications en ma présence et n’a rien trouvé de particulier, tout allait bien, le problème semblait donc être du côté de Sipartech.
Ils nous ont annoncé être dans l’incapacité d’envoyer un technicien dans l’immédiat pour remettre le lien en service, le rendez-vous a donc pris pour le lendemain afin d’effectuer un diagnostic avec le technicien, ce qui m’a fait perdre une demi-journée de plus.
Le technicien est bien passé le lendemain et a vérifié à l’aide d’un réflectomètre (appareil permettant en connaitre la longueur d’une fibre). Il a bien vu un problème au niveau de leur baie, un laser est laissé de notre coté du lien pour vérifier l’emplacement du point de coupure. Après s’être déplacé jusqu’à leur baie, nous avons pu constaté que la fibre était mal soudée au niveau de la cassette (l’endroit où l’on soude deux câbles de fibres entre eux).
Le technicien n’ayant pas le matériel pour effectuer la soudure, il a du appeler un soudeur indépendant afin de réaliser la réparation. Celui-ci a mis 30 min pour arriver sur place et a réalisé de nouvelles soudures afin de mettre en service le lien.
Une expérience douloureuse …
Cette mauvaise expérience a laissé quelques doutes sur la capacité de Sipartech à mettre en place du premier coup et rapidement des liens de fibres optiques.
Mais le lien a fini par être fonctionnel et depuis aucune panne n’est à déplorer. Le débit sur site a été multiplié par 50 et le confort d’utilisation est bien meilleur, vu que le lien ne sature plus.
Pour ce projet, j’ai du une nouvelle fois être autonome et organisé pour préparer les visites sur site, et les multiples interventions sur site afin de faire fonctionne le lien.
Une connaissance des liens fibres et de la technologie WDM est nécessaire pour pouvoir diagnostiquer correctement et pour ensuite contacter les bons supports.
Compétences : Planification, Autonomie, Réseau – Fibre et WDM
Déploiement du 802.1X
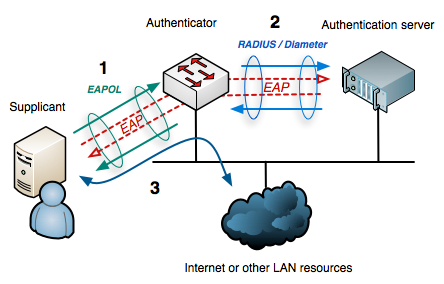
Une sécurité du LAN inexistante
Le réseau filaire d’une entreprise est souvent dépourvu de toute sécurité liée à l’accès de celui-ci. Il suffit souvent de brancher un câble Ethernet pour accéder au réseau, contrairement au Wi-Fi où il faut un mot de passe pour accéder à celui-ci.
L’entreprise dispose d’un réseau LAN (réseaux locaux de l’entreprise) neuf de dernière génération, remplacé au fur et à mesure de mon alternance, compatible avec toutes les technologies modernes, dont le 802.1x qui permet d’ajouter une couche de sécurité lors de la connexion d’un poste au réseau filaire.
Cette sécurité est très semblable au système utilisé sur le Wi-Fi appelé WPA Entreprise. Il permet au système d’authentification de la borne d’aller demander à un serveur (souvent RADIUS) si un utilisateur a bien le droit d’être connecté au réseau.
Afin de renforcer la sécurité de notre LAN filaire, l’équipe Sécurité a souhaité la mise en place de la technologie 802.1X sur nos switchs.
Mise en place
Une démonstration de la faisabilité avait déjà été effectué par un collègue de l’Administration Windows avant mon arrivée mais cela n’avais pas encore été mis en place.
J’ai ainsi pu découvrir cette technologie et finir de peaufiner les paramètres avant que je la déploie sur l’intégralité des switchs du parc.
L’authentification est réalisée par des serveurs RADIUS connecté à l’AD (serveur central de gestion Windows en entreprise) ainsi que par un « certificat machine » délivré par la PKI (Public Key Infrastructure) interne.
Il a été décidé que le serveur RADIUS, suivant le client qui se présente sur le switch, attribue à la personne le VLAN correspondant à l’étage sur lequel il est connecté.
Cette attribution de VLAN via RADIUS nous permet également de bloquer les personnes ne faisant pas leurs mises à jour de poste en les envoyant sur un réseau qui ne leur permet de faire que les mises à jour Windows.
Si le PC n’est pas reconnu, il est automatiquement envoyé vers le réseau Invité.
Ce déploiement a été fait par vague sur la plage horaire du midi afin de prévenir tout problèmes d’accès non prévu lors de la démonstration de faisabilité originale.
On m’a également demandé de tester cette technologie sur des switchs Aruba ProCurve dans l’éventualité où nous devrions changer de fournisseur de switchs, ce qui m’a permis de configurer entièrement cette solution sur cette plateforme.
L’équipe Sécurité à mis notre disposition une suite logicielle complète « ELK« (ElasticSearch, Logstash, Kibana) permettant un traitement rapide et efficace des messages de debug provenant des différents serveurs RADIUS présents sur les différents sites.
Une sécurité renforcée efficacement
Ce projet m’a permis d’en apprendre énormément sur la sécurité que l’on peut mettre en place sur un LAN physique ainsi que sur les possibilités offertes par les serveurs RADIUS fournis sur Active Directory.
Mon tuteur m’a comme d’habitude fait entièrement confiance sur cette partie en me laissant réaliser ce projet comme je l’entendais, ce qui m’a demandé une préparation en amont de sa mise en œuvre ainsi que de l’organisation dans son déroulement.
Compétences : Planification, Autonomie, Windows – RADIUS